FOSCAR 알고리즘 스터디 1주차 2조 블로깅
1주차 코드리뷰 블로깅 : 조영상
*성능평가 이론 출처 : 이것이 코딩테스트다 with Python [이것이 코딩테스트다 with Python] [이것이 코딩테스트다 with Python]
스터디 내용 중 혹시 틀리거나 잘못된 부분이 있을 때 정말 가감 없이 지적해 주시면 부족한 제가 성장하는데 큰 도움이 될 것 같습니다. 감사합니다!
코딩테스트 강의를 듣다가 시간초과를 대비하여 코딩을 하기 이전에 시간복잡도를 어느정도 감으로 고려하면서 설계한다고 해서 해당 예제에 적용해 보았고 정리한 강의 내용을 함께 적어보았습니다.
알고리즘의 복잡도
1. 시간 복잡도 : 소스코드가 실행되는데 소요되는 시간
2. 공간 복잡도 : 소스코드가 실행되었을 때 사용되는 메모리 공간
프로그래밍에서는 위의 두 가지 복잡도가 낮을수록 좋다.
그런데 위에서 설명한 정성적인 설명으로는 복잡도에 대한 수치적 비교우위를 정할 수 없다.
우리는 이를 Big O(빅 오)라고 하는 함수적 표현을 통해 복잡도에 대한 개념을 수치적으로 표현할 것이다.
Big O 표기법 : 소스코드의 수행시간을 소스코드만을 통해 계산하고자 할 때 연산 횟수에 대한 함수로 표시하게 되는데 이 대 이 함수식의 최고차 항만을 고려하여 복잡도를 계산한 것이다.
ex)
시간복잡도 = 3n^2 + 2n^2 + 9
라고 할 때
이를 Big O포기법으로 나타내면 O(N^3)이라고 할 수 있다.
이때 최고차항 만을 고려하는 이유 : CPU의 연산 속도는 비교적 큰 수에 해당하므로 극한값에 대한 유횻값을 고려하는 것이 합리적이기 때문이다.
그렇다면 알고리즘의 성능을 나타낼 수 있는 시간복잡도 함수에서의 최고차항으로 표현될 수 있는 함수들은 어떤 것들이 있을까?
좋음<-------------------------------------------------------------------------------------------------------------->나쁨
상수 O(1) , 로그(logN) , 선형 O(N) , 로그선형 O(NlogN) , 이차 O(N^2) , 삼차 O(N^3) , 지수 O(2^N)
프로그램에 입력되는 자료 N의 범위에 따라 연산 횟수가 많아질수록 좋지 못한 코드이고(입력 자료 대비 수행시간이 오래 걸림) 반대로 자료 N의 범위가 무엇이든 간에 연산 횟수가 일정한 연산 횟수에 수렴하거나 더 이상 증가하지 않는 경우 좋은 코드(수행시간이 적게 걸림)라고 할 수 있다.
알고리즘 시간 복잡도 계산 예제
예제 1) 리스트에 있는 모든 항들의 값을 더하는 프로그램
#########################
array= [1,2,3,4,5,6]
summary = 0
#########################
for x in array:
summary += x
#########################
print(summary)array =[1,2,3,4,5]
###########################
for x in array:
for y in array:
k = x*y
print(k)시간 복잡도를 고려한 설계 매뉴얼은 대략 다음과 같다.
만약 문제에서 시간제한이 1초라고 했을 때
N의 범위가 500인 경우 O(N^3)으로 설계해야 한다.
N의 범위가 2,000인 경우 O(N^2)으로 설계해야 한다.
N의 범위가 100,000인 경우 O(NlogN)으로 설계해야 한다.
N의 범위가 10,000,000인 경우 O(N)으로 설계해야 한다.
즉, N의 범위가 많을수록 일반적인 연산시간이 증가할 수 있기 때문에 알고리즘 성능시간을 줄일 수 있는 방향으로 설계해야 한다.
알고리즘 문제 해결 과정
1. 지문 읽기 및 컴퓨터적 사고
2. 요구사항(복잡도) 분석
3. 문제 해결을 위한 아이디어 찾기
4. 소스코드 설계 및 코딩
Python에서 수행시간 측정 방법
import time
#time.time()은 현재 시간값을 가져와 준다.
start_time = time.time() # 현재시간(알고리즘이 시작되기 직전)을 start_time변수에 저장한다.
###########################
#알고리즘 구현부
###########################
end_time = time.time() # 현재시간(알고리즘이 끝난 직후)을 end_time변수에 저장한다.
print("time: ", end_time - start_time)
DNA 문제 1969번
1969번: DNA
DNA란 어떤 유전물질을 구성하는 분자이다. 이 DNA는 서로 다른 4가지의 뉴클레오티드로 이루어져 있다(Adenine, Thymine, Guanine, Cytosine). 우리는 어떤 DNA의 물질을 표현할 때, 이 DNA를 이루는 뉴클레오
www.acmicpc.net
- 문제 풀이
그림을 봐야 이해하기 편해서 인용해 왔습니다.!
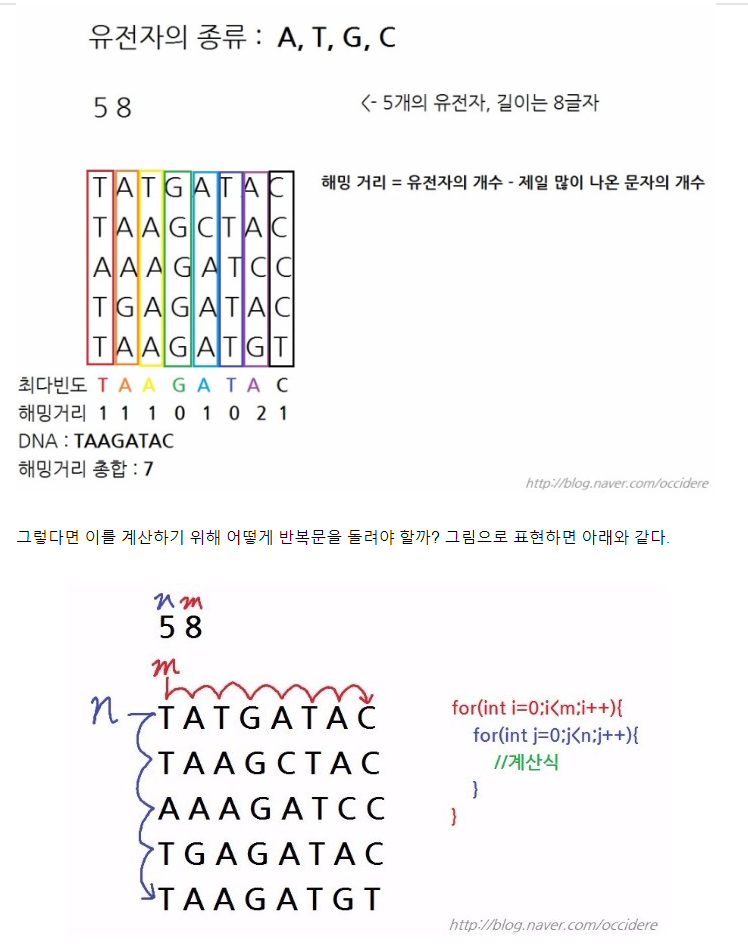
# 문제의 목적은 여러가지 염기서열들 중에 각자리별로 최다 빈도를 갖는 문자를 선정하여
# 하나의 대표 염기서열을 선정하는데에 있다.
# 그 방법으로 최다 빈도 문자를 제외한 문자들의 갯수의 최솟값(HD변수에 추가)을 찾는 것을 선택했다.
#시간복잡도를 계산하였을 떄 N의 범위를 최대 1000으로 잡을 수 있기 떄문에
# O(N^2)의 시간 복잡도로 설계하였을 때 1초이내에 실행된다고 할 수 있다.
n,m = map(int, input().split()) #m개의 문자로 이뤄진 묶음을 n묶음 만들겠다.
arr=[]
result = ''
for i in range(n):
arr.append(list(map(str,input()))) #m개의 문자들을 문자형으로 리스트로 n묶음 추가한다. 2차원 리스트
HD = 0 #최빈 문자를 제외한 다른 문자의 빈도수 합
for i in range(m):
a,c,g,t =0,0,0,0
#같은 m값에 대해 다른 DNA들을 검사하는 것이므로, 이차원 리스트 상의 첫번째 열을 검사한다.
for j in range(n): #만약 j가 1이고 m도 1일 때
if arr[j][i] =='T': # 1행 1열의 문자검사 //다음 for문에서는 2행 1열의 문자 검사//다음 for문에서는 3행 1열의 문자 검사
t +=1 #맞으면 1추가
elif arr[j][i] == 'A':
a += 1
elif arr[j][i] == 'C':
c += 1
elif arr[j][i] == 'G':
g += 1
#위의 for문이 끝나면 행렬(2차원 리스트)의 한열에 대해서 문자의 갯수파악이 완료된다. (소문자 변수 a,c,g,t에 저장됨)
#일단 만약 1열에 대한 문자파악이 완료되었다 치면
if max(a,g,t,c) ==a: # 1열에 대해서 어떤 문자가 가장 많이 나왔는지 파악하고
result += 'A' #가장 많이 나온 문자에 대해 최종 DNA 서열에 추가시킨다.(최종 염기서열의 1열(첫번째 문자 획득))
HD += g+t+c # 최빈 문자를 제외한 나머지 문자들의 빈도수를 HD이라는 변수에 저장한다.
elif max(a,g,t,c) ==c:
result += 'C'
HD += a+g+t
elif max(a,g,t,c) ==g:
result += 'G'
HD += a+t+c
elif max(a,g,t,c) ==t:
result += 'T'
HD += a+g+c
# 안쪽 for문은 통해 1개의 세로줄씩 검사가 끝나고,
#가장 바깥 for문이 실행되었을 때 비로소 모든 열에 대한 검사가 끝나게 된다.
print(result)# 최종적으로 각 열마다의 최빈 문자열의 결과를 하나의 염기서열로 보여준다.
print(HD)# 최솟값을 연산한다.'FOSCAR-(Autonomous Driving) > 알고리즘 스터디' 카테고리의 다른 글
| [2023 알고리즘 스터디] 5조 #2주차 - 그리디 (1) | 2023.02.04 |
|---|---|
| [2023 알고리즘 스터디] 1조 오현민 #1주차 - 백준 10870, 2525, 1712, 4673 (1) | 2023.01.29 |
| [2023 알고리즘 스터디] 4조 #1주차 - 백준 3085번(사탕 게임), 24954번(물약 구매) 문제 풀이 (2) | 2023.01.29 |
| [2023 알고리즘 스터디] 3조 #1주차 - 백준 1316, 1475, 2960, 3085번 코드 리뷰 (1) | 2023.01.29 |
| [2023 알고리즘 스터디] 5조 #1주차 - 구현, 브루트포스, 스트링 (1) | 2023.01.28 |

